生成字幕技術
01. 功能概述 (Overview)
生成字幕模組 採用了 OpenAI 開源的 Whisper Series (Fast-Whisper 實作) 作為辨識核心。它能將任何主流影片或錄音檔 (如 MP4, MKV, MP3, M4A, WAV, FLAC, AAC, OGG 等),自動轉錄為精確的時間軸字幕 (SRT/VTT)。
本系統不僅支援單純的字幕生成,更整合了 自動翻譯、雙語字幕 排版,以及一鍵 自動壓制 (Burn-in) 功能,讓您無需開啟其他剪輯軟體,即可產出帶有字幕的成品影片。
02. AI 核心參數詳解
🧠 AI 模型選擇 (Model Selection)
我們提供了四種不同等級的模型,您可以根據電腦效能與精確度需求進行選擇:
- medium (中):速度快 VRAM: ~2GB
適合一般對話清晰的影片,速度最快,但對專有名詞或快速語速的辨識度稍弱。 - large-v2 (佳):平衡型 VRAM: ~4GB
目前最穩定的版本,在辨識率與速度之間取得很好的平衡,適合大多數 YouTube 影片。 - large-v3-turbo (優):新技術 VRAM: ~6GB
針對速度優化的 V3 版本,保留了 V3 的高辨識特性但運算更快。 - large-v3 (最優):最高品質 VRAM: ~10GB+
OpenAI 最新最強大的模型,對多語言混雜、口音、背景噪音的抗性最強,但需要強大的顯卡與記憶體。
🗣️ 影片語言 (Video Language)
指定影片中講話的語言。雖然設為 Auto (自動偵測) 通常準確,但若影片對白很少或背景音樂很大,手動指定語言 (如 Chinese (中文))
可以大幅提高準確率。
⚙️ 處理模式 (Processing Mode)
- Auto-Translate (自動轉繁中):無論影片是英文、日文還是韓文,系統會自動翻譯並輸出為「繁體中文」字幕。
- Original (原文字幕):影片講什麼語言,就輸出該語言的字幕 (例如日文影片輸出日文字幕)。
📝 自訂提示詞 (Initial Prompt)
遇到專有名詞或是特殊人名總是翻錯嗎?您可以在此文字框內手動輸入希望 Whisper 模型優先識別的專有名詞或字詞庫。這能引導 AI 在轉錄時優先套用您設定的詞彙,大幅提升語音辨識的精準度,省去後期大量校稿的時間!
⏳ 進度與剩餘時間 (ETA) 估算
系統在產出字幕的進度列中,內建了即時的「進度與剩餘時間 (ETA) 估算」顯示,全面支援 CPU 與 GPU 運作模式。影片字幕還要跑多久,一目了然,讓您更容易掌握工作時間安排。
🛡️ VAD 濾除雜音 (Voice Activity Detection)
這是一個非常重要的功能。勾選後,AI 會在辨識前先分析「哪裡有人聲」。
用途:防止 AI 在純音樂片段或無聲片段產生「幻覺字幕」(如無意義的符號或重複字詞)。
建議:視情況手動開啟。最新版本預設為關閉,以避免誤刪輕聲細語的對白。
👥 分辨說話者 (Speaker Diarization)
使用 Pyannote AI 進行音軌分離,自動辨識影片中有幾個人在說話,並將對應的發言人標籤 (例如 [SPEAKER_00]:,
[SPEAKER_01]:) 標註在字幕開頭。
🔑 首次使用與授權確認: 系統會彈出視窗要求輸入 Hugging Face Access Token (需以
hf_ 開頭)。這是一項免費服務。如果您遇到授權相關錯誤,請按照以下步驟確認:
- 前往 pyannote/speaker-diarization-3.1 與 pyannote/segmentation-3.0 這兩個模型頁面。
- 確保您已登入 Hugging Face 帳號。
- 如果您尚未同意授權,頁面上會出現一段協議和表單,請填寫並按下 "Agree and access repository"。
- 如果您點進去直接看到模型介紹和檔案列表 (Files and versions),就代表您已經成功授權了!
03. 字幕輸出與外觀 (Output & Style)
📄 輸出格式
- SRT:最通用的字幕格式,包含時間軸與文字。
- VTT (WebVTT):網頁專用的字幕格式,支援簡單樣式。
- TXT:純文字檔,不含時間軸,適合用來整理逐字稿。
- 自動壓制影片 (Auto Burn-in):將字幕「烙印」在影片畫面上,生成一個新的 MP4 檔。
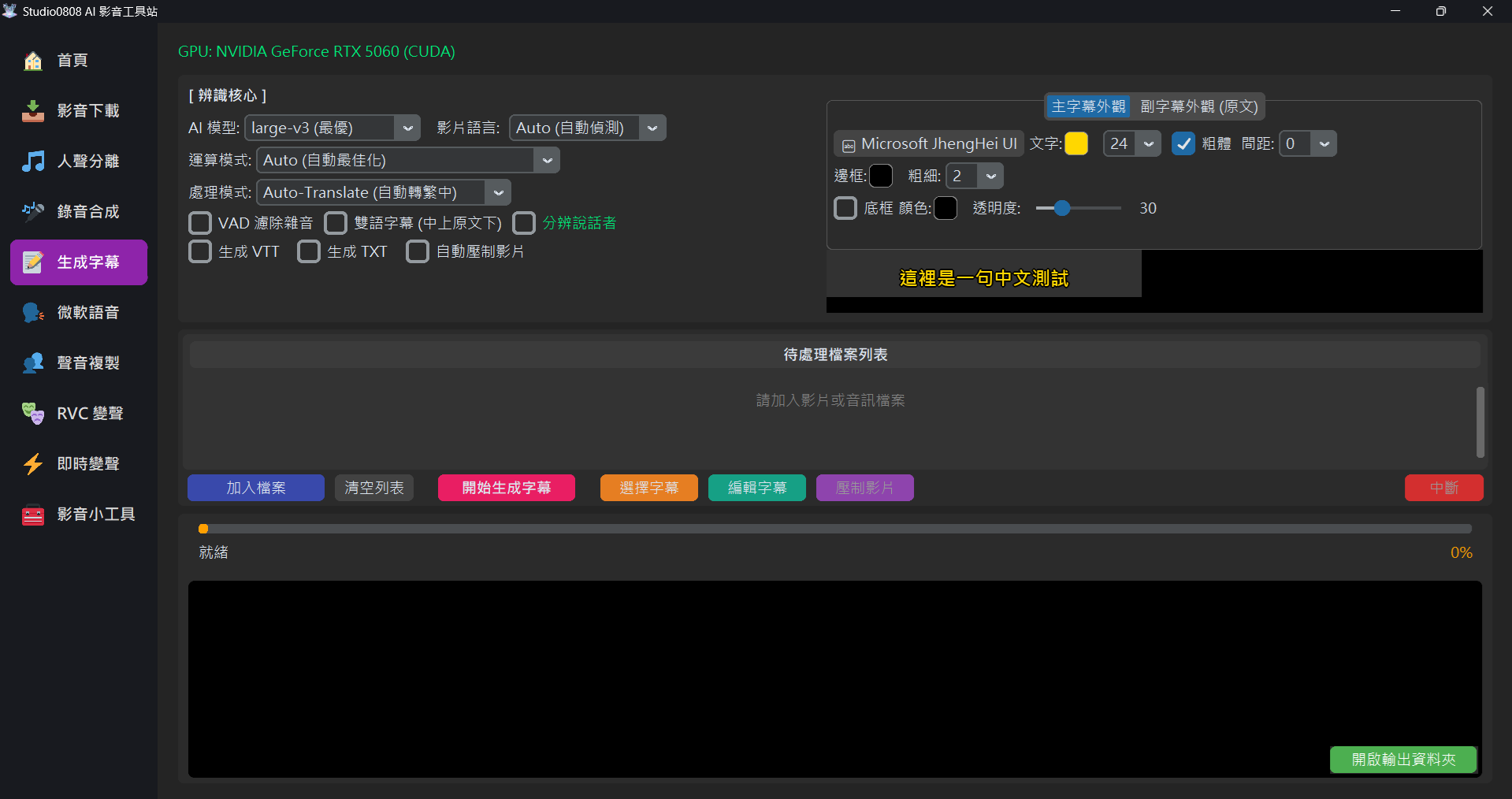
🎨 獨立外觀設定 (全台首創無損 ASS 雙引擎)
我們的字幕生成核心採用了強大的 雙層疊加動態計算引擎,不僅保證與所有影片解析度的相容,還能讓「主字幕」與「副字幕 (原文)」擁有完全獨立的外觀設計,互不干擾!
在介面右側,我們提供了直覺的 分頁標籤 (Tabview):
- 主字幕外觀: 控制翻譯後的主要語言 (通常為中文)。
- 副字幕外觀 (原文): 控制底下的第二語言 (只有在勾選「雙語字幕」時才會顯示)。
在每個分頁中,您可以 獨立設定 以下參數,且設定會即時連動上方的 字幕預覽 (Preview):
- 字型 (Font) 與 粗體 (Bold):點擊按鈕可選擇系統內安裝的所有字型 (如微軟正黑體)。
- 顏色 (Color) 與 大小 (Size):隨意調配您的文字色彩。
- 字元間距 (Spacing):自訂字幕字與字之間的距離 (支援 0~30 的設定值),讓排版更具彈性。
- 邊框 (Outline):單獨加粗文字外圍的描邊,防眩光。
- 底框 (Background Box):在文字後方加上半透明的自定義底色 (極致的 Netflix 觀影體驗)。透過底層的
PrimaryStyle/SecondaryStyle運算技術,即使兩行開啟不同顏色的底框疊加也絕不會破版!
04. 常見問題 (Troubleshooting)
Q: 出現 "VRAM OOM" 或 "System RAM OOM" 錯誤?
原因:電腦的記憶體不足以載入大型模型。
解法:請將模型降級為 medium (中) 或 large-v2
(佳)。效果差異通常不大,但能讓程式順利執行。
Q: 壓制出來的影片沒有聲音?
解法:此問題已在最新版本修復。系統現在會強制抓取原始音軌並轉碼為 AAC 格式,確保聲音完整保留。
Q: 雙語字幕 (Bilingual) 是什麼?
A: 這是學習外語的神器!勾選後,系統會同時顯示「翻譯後的中文」與「原文」,並自動排版 (中文在上,原文在下)。