微軟語音合成技術
01. 核心技術介紹
本程式 整合了微軟最新的 Edge-TTS (Azure Cognitive Services) 技術,讓您無需申請複雜的 API 金鑰,即可免費使用高品質的 AI 神經網路語音。
與傳統機械音不同,Neural TTS 模型能生成極其自然、抑揚頓挫、且帶有情感的人聲,廣泛應用於:
- 🎬 影片旁白:為解說影片、短影音快速配音。
- 📚 有聲書製作:將長篇文章轉為語音朗讀。
- 🎤 角色扮演:透過多角色設定,一人分飾多角演出對話。
02. 功能特色解析
🌍 多國語言支援
系統內建支援多種語言模型,包含:
- 中文 (Chinese):台灣口音 (曉臻、雲哲)、大陸口音 (曉曉、雲希)、粵語等。
- 英文 (English):美式 (Jenny)、英式 (Ryan) 等,發音標準道地。
- 日韓與其他:完整的日語、韓語、法語、德語支援。
🎛️ 進階參數控制 New!
為了滿足更細緻的聲音需求,本封測版本加入了強大的獨立控制功能:
- 語速 (Speed):支援
-50%(慢速) 到+50%(快速) 的全域調整。 - 音調 (Pitch):支援 5 個角色 獨立音調設定。
- 想讓 **男童 (Boy)** 聲音更稚嫩?試試
+20Hz或+30Hz。 - 想讓 **男聲 (Man)** 更沉穩?試試
-20Hz或-30Hz。
- 想讓 **男童 (Boy)** 聲音更稚嫩?試試
03. 使用模式說明
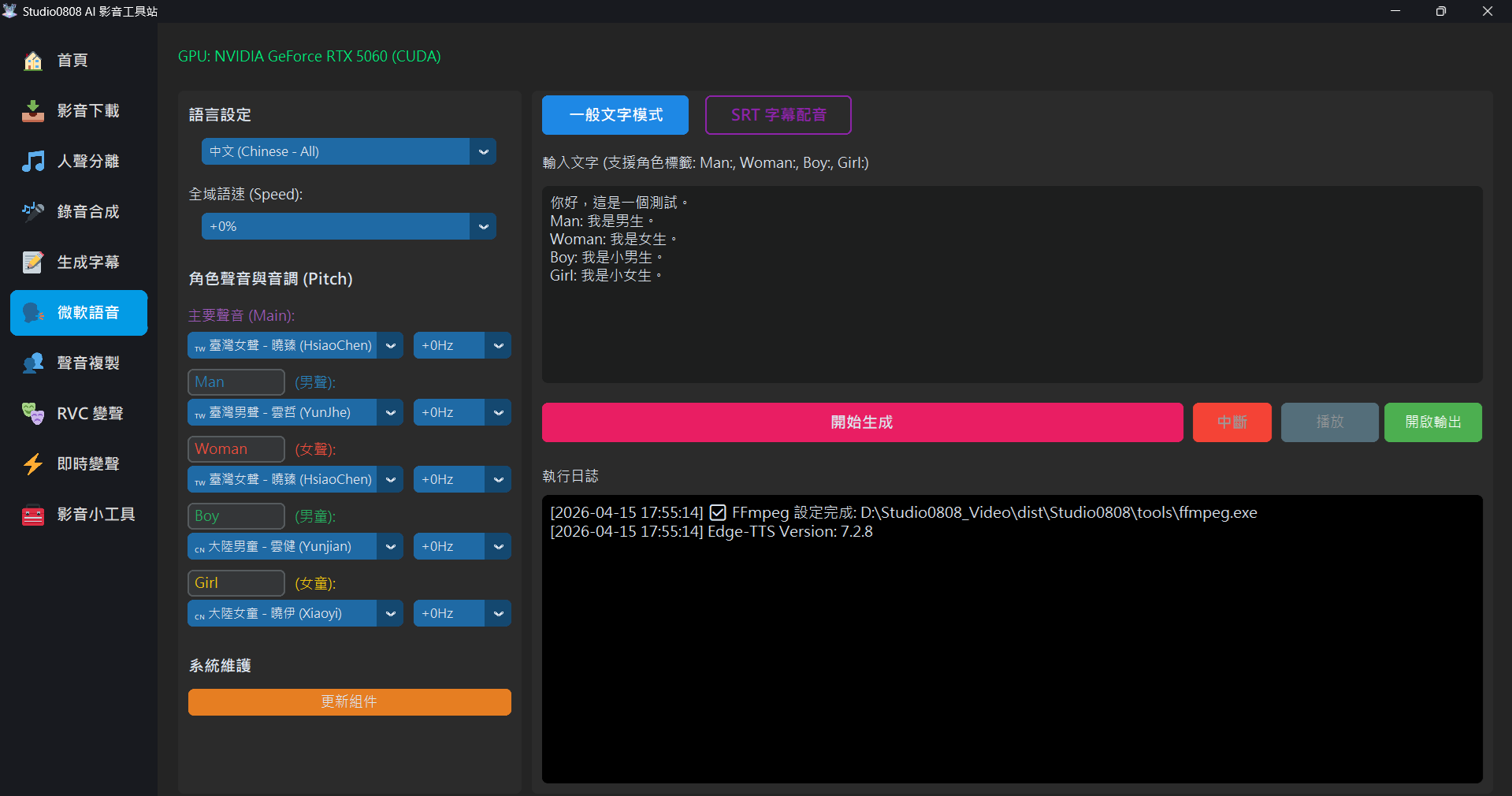
📝 一般文字模式 (Text Mode)
直接輸入文字即可生成語音。支援特殊的 **「角色標籤」** 功能,讓您在同一段文字中切換不同聲音:
Man: 你好,我是爸爸。
Woman: 嗨,我是媽媽。
Boy: 我是小明!
Girl: 我是小美~
(無標籤): 這是旁白聲音。系統會自動依據標籤切換對應的角色設定 (包含您設定的獨立音調)。
🎬 SRT 字幕配音模式 (SRT Dubbing)
直接載入 .srt 字幕檔,系統會依據字幕的時間軸生成語音。
- 智慧避讓 (Smart Anti-Overlap):如果上一句還沒唸完,下一句會自動順延,確保聲音不重疊。
- 字幕清洗 (SRT Cleaner):針對雙語字幕 (如中日對照),可使用 🧹 只保留中文 功能,一鍵去除外語,避免 AI 朗讀出不必要的原文。
04. 常見問題 (Q&A)
Q: 出現 "403 Forbidden" 錯誤?
A: 這是因為微軟更新了 API 驗證機制。請點擊介面左下角的 🔄 更新組件 (Fix 403) 按鈕,系統會自動更新
edge-tts 核心組件來修復此問題。
Q: 為什麼顯示「【某某語言模型】 無法朗讀中文內容」?
A: 雖然部分外語模型 (如日文模型) 也能讀漢字,但發音通常不準確。如果您輸入中文內容卻選擇了外語模型 (例如德文、法文等),系統會自動偵測並發出明確的警告 (精準標示出是哪個模型不匹配),避免生成錯誤或無聲的音訊。
Q: 雲澤 (Yunze) 聲音不見了?
A: 微軟官方似乎已移除了雲澤模型。建議改用 **雲希 (Yunxi)** 並搭配 **音調調整** 來模擬類似的聲音。
Q: 怎麼把生成的語音直接播給 Discord 裡的朋友聽?
A: 由於語音合成是把聲音輸出到您的喇叭,朋友是聽不到的。您可以透過兩種方式分享:
- 使用 立體聲混音 (Stereo Mix):在 Discord 把麥克風改成「立體聲混音」,這樣您電腦播出來的合成語音,朋友就聽得到了(但同時也會聽到您看影片的聲音)。
- 使用 VB-Audio Virtual Cable(推薦):去 Windows
音效設定,把播放合成語音的軟體(或系統預設輸出)指派給
CABLE Input,然後在 Discord 麥克風選擇CABLE Output,這樣就能乾淨的只傳送合成出來的語音!
05. 技術規格 (Specs)
- 核心引擎 (Core Engine):Microsoft Edge Read Aloud API (微軟大聲朗讀技術)
- 音訊格式 (Format):MP3 (中間運算格式) / WAV (最終輸出封裝,方便後製)
- 音質取樣 (Sample Rate):24kHz / 48kHz (高解析度音質)
- 網路需求 (Network):必須保持網際網路連線 (使用雲端即時運算)